Modeling the Visibility Distribution for Respondent-Driven Sampling with Application to Population Size Estimation
Abstract
Respondent-driven sampling (RDS) is used throughout the world to estimate prevalence and population size for hidden populations. Although RDS is an effective method for enrolling people from key populations in studies, it relies on a partially unknown sampling mechanism and thus each individual’s inclusion probability is unknown. Current estimators for population prevalence, population size, and other outcomes rely on a participant’s network size (degree) to approximate their inclusion probability in the sample from the networked population. However, in most RDS studies, a participant’s network size is attained via a self-report, and is subject to many types of misreporting and bias. Because design-based inclusion probabilities cannot be exactly computed, we instead use the term visibility to describe how likely a person is to be selected to participate in the study.
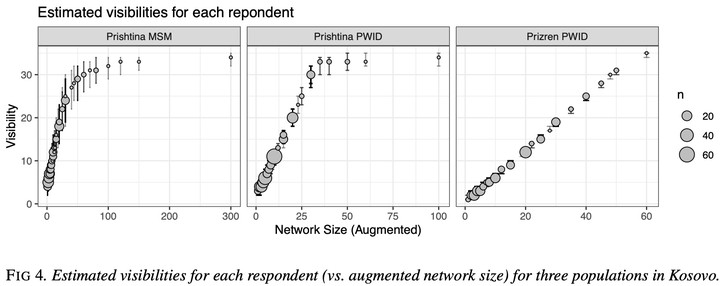
The commonly used successive sampling population size estimation (SS-PSE) framework to estimate population sizes from RDS data relies on self-reported network sizes in the model for the sampling mechanism. We propose an enhancement of the SS-PSE framework that adds a measurement error model for visibility used in place of the self-reported network size and a model for the number of recruits an individual can enroll. Inferred visibilities are a way to smooth the degree distribution and bring in outliers, as well as a mechanism to deal with missing and invalid network sizes.
We demonstrate the performance of visibility SS-PSE on three populations from Kosovo sampled in 2014 using RDS. We also discuss how the visibility modeling framework could be extended to prevalence estimation.